The Post
It’s actually WIP - most of the ideas are here but I still need to review it and think a bit more about the options I want to explore later..
Problem Statement
Let’s say we have “multi-tenant GKE clusters” where many tenants deploy their workloads and have their own namespaces… they dont access the namespaces directly, they deploy through a pipeline and manage everything without kubectl (from a IDP). PII and NON-PII data must go into different locations, PII must go to the Enterprise Security Log Management (ESLM) location and NON-PII can either go into the tenant’s GCP project or to another application. How can we route these logs?
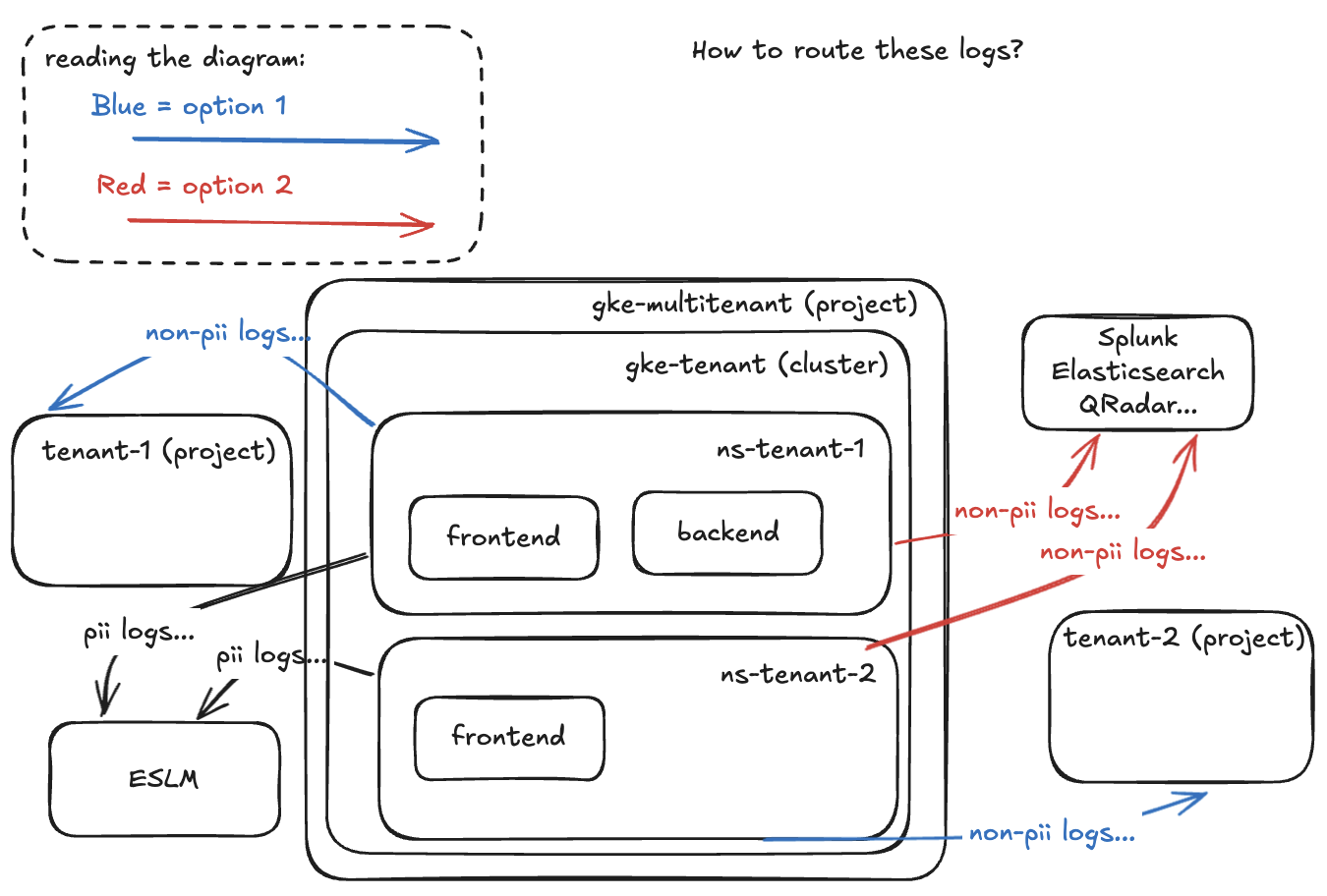
Options
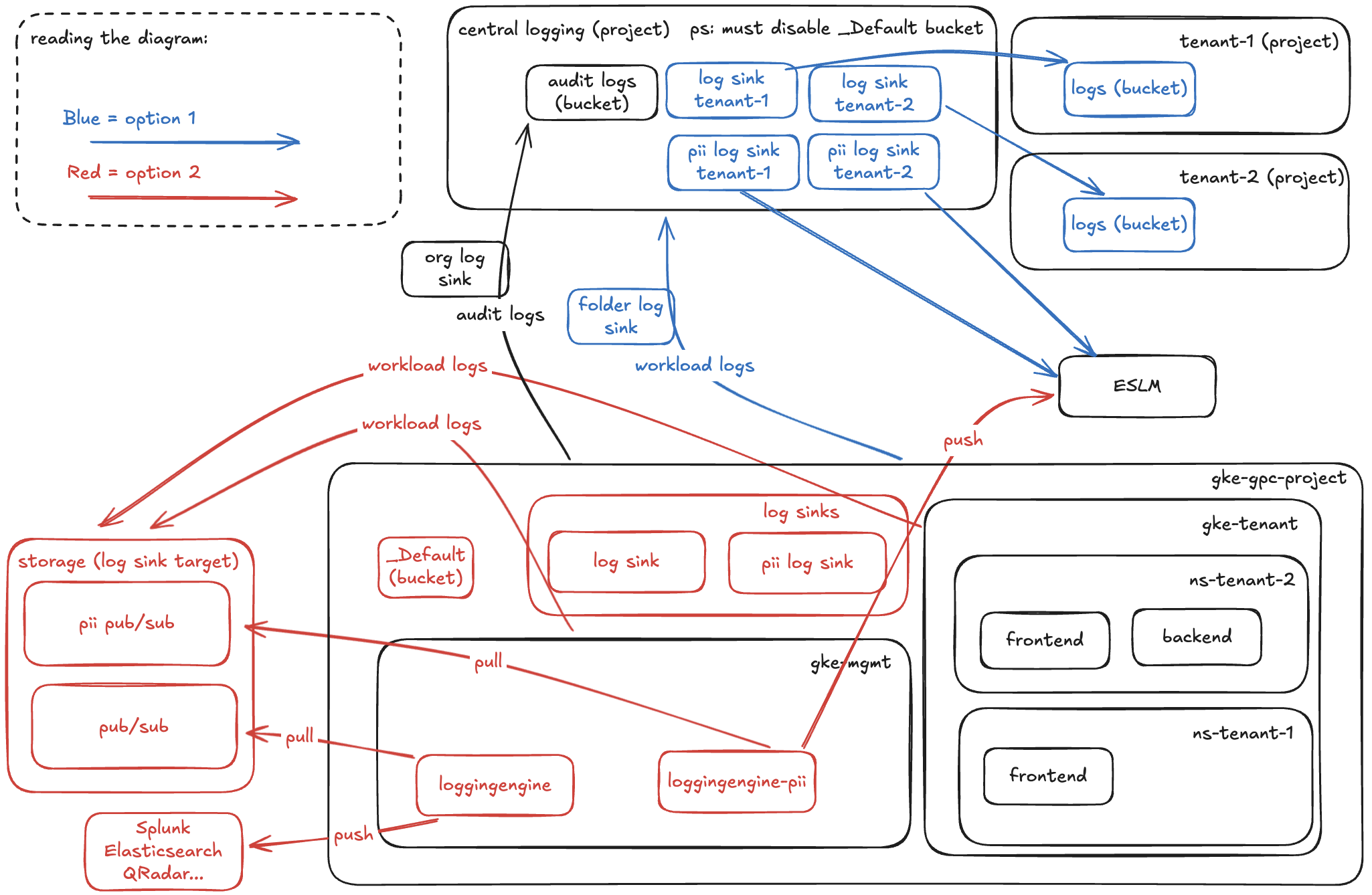
Option 1 - central logging + per-project
Each tenant/client must have a gcp project and in that project a bucket (or some other storage, like BigQuery, for example). We configure log sinks to the individual projects from a central logging project.
Option 2 - log forwarder
Log forwarder or logginengine is a container that will forward logs to where we want them to go. We can build that image ourselves and control what it will do with the logs it consumes from the pub/sub. We would have a more static number of log sinks in the gke-gcp-project but the logs would be duplicated in GCP (because of _Default bucket which would be too risky to disable) and the external logging solution (Elasticsearch, Splunk, etc).
Comparing
PS: We have to exclude PII data from being stored in the _Default bucket and store it in a separate persistent storage if forwarding to ESLM is not enough.
| Comparison Criteria | Option 1 - central logging + per-project | Option 2 - log forwarder |
|---|---|---|
| Scaling | Scales with number of namespaces - All resources managed by GCP - might hit the log sink limit in a GCP project (around 200 but can be increase) and will have to create/maintain log sinks per project | Scales with number of clusters - We have to care about scaling the logforwarders but the more clients the more replicas (we can configure autoscale) and no need to create anything else manually. |
| Cost | ✅ Log sinks and storage in individual tenant projects | ⚠️ Compute for logforwarders, pub/subs, and increased cost for duplicated logs in _Default bucket and external logging solution |
| Chargeback | ✅ Chargeback in the tenant’s project | ⚠️ Shared cost or we have to come up with a clever solution to individually charge tenants per log volume for _Default, compute for log forwarder, and pub/sub. Also need to pay for the external logging solution |
| Isolation | ✅ In individual projects | Depends on external logging solution (usually centralized) |
| Modifying Logs | ⚠️ No, cannot modify logs | ✅ Can modify logs on the fly (append, prepend.. modify/include metadata) |
| Solution Flexibility | ⚠️ We are limited to the targets GCP allows us to set for log sinks | ✅ We can push these logs pretty much anywhere as we control the log forwarders code |
| Operational Complexity | Very little maintenance if the list of clients is static but if the list is dynamic it might be problematic to maintain the individual log sinks for each project | We have to maintain the image for logforwarder, the deployment and any dependencies, besides some maintenance for pub/sub, buckets, and log sinks |
| Performance & Latency | ✅ Logs should be available instantly | ⚠️ It can take a while for logs to be processed and forwarded |
| Reliability | GCP | GCP, log forwarder and external logging solution |
| Routing Complexity | High as we have to have a way to make sure the log sinks are indeed sending logs properly to individual projects (IaC is a must) | Very low as we only need to care about one target |