This Post
This post is pretty broad, here is the table of contents:
KPIs, SLOs, SLIs, SLAs and Golden Signals
| Term | What is it used for? What is it? |
|---|---|
| Key Performance Indicators (KPI) | It’s what we measure to know how we are doing |
| Golden Signals | The most important metrics that often help solve INCs quickly |
| Service Level Indicators (SLI) | Are the limits/targets/metrics that we want to track/view, alert on, etc. |
| Service Level Objective (SLO) | Are the numerical/percentage/etc definitions of the SLIs |
| Service Level Agreement (SLA) | Formal agreement between service provider and a client |
I will try to go cover some basics/tips on them and everything will come together in the Bringing Everything Together section.
Golden Signals
The 4 golden signals defined by Google’s SRE handbook are:
- Latency
- Traffic
- Errors
- Saturation
I’m not going to rewrite what is in the SRE handbook. I personally use that section from the handbook to kick off any sort of conversation around what we should be monitoring and to guide me on what is actually important.
KPIs
Similar to SLOs; but these are broader objective definitions focused mostly on sharing the SLOs with leadership and to help create OKRs.
SLOs and SLIs
The best way, to me, to understand and define new SLOs and SLIs is looking into Golden Metrics and the existing SLIs and SLOs defined (some examples might help too). Also it’s important to continously look back into incidents to know what else we should be measuring to prevent INCs from happening again.
Some examples:
-
Availability
- SLI: Percentage of successful HTTP requests (e.g., 2xx/total requests).
- SLO: 99.9% of HTTP requests must succeed over a 30-day rolling window.
-
Latency
- SLI: 95th percentile of response time for HTTP requests.
- SLO: 95% of HTTP requests must have a response time under 200 ms over a 7-day window.
-
Error rate
- SLI: Rate of 5xx server errors as a percentage of total requests.
- SLO: Fewer than 0.1% of requests should return a 5xx error over a 1-week period.
-
Multi-region availability
- SLI: Percentage of requests served successfully from both primary and backup regions.
- SLO: 99.99% of cross-region requests must succeed per quarter.
-
Uptime
- SLI: Number of minutes the service is reachable in a calendar month.
- SLO: The service must be reachable 99.95% of the time per month (i.e., < 22 minutes of downtime per month).
Bringing Everything Together
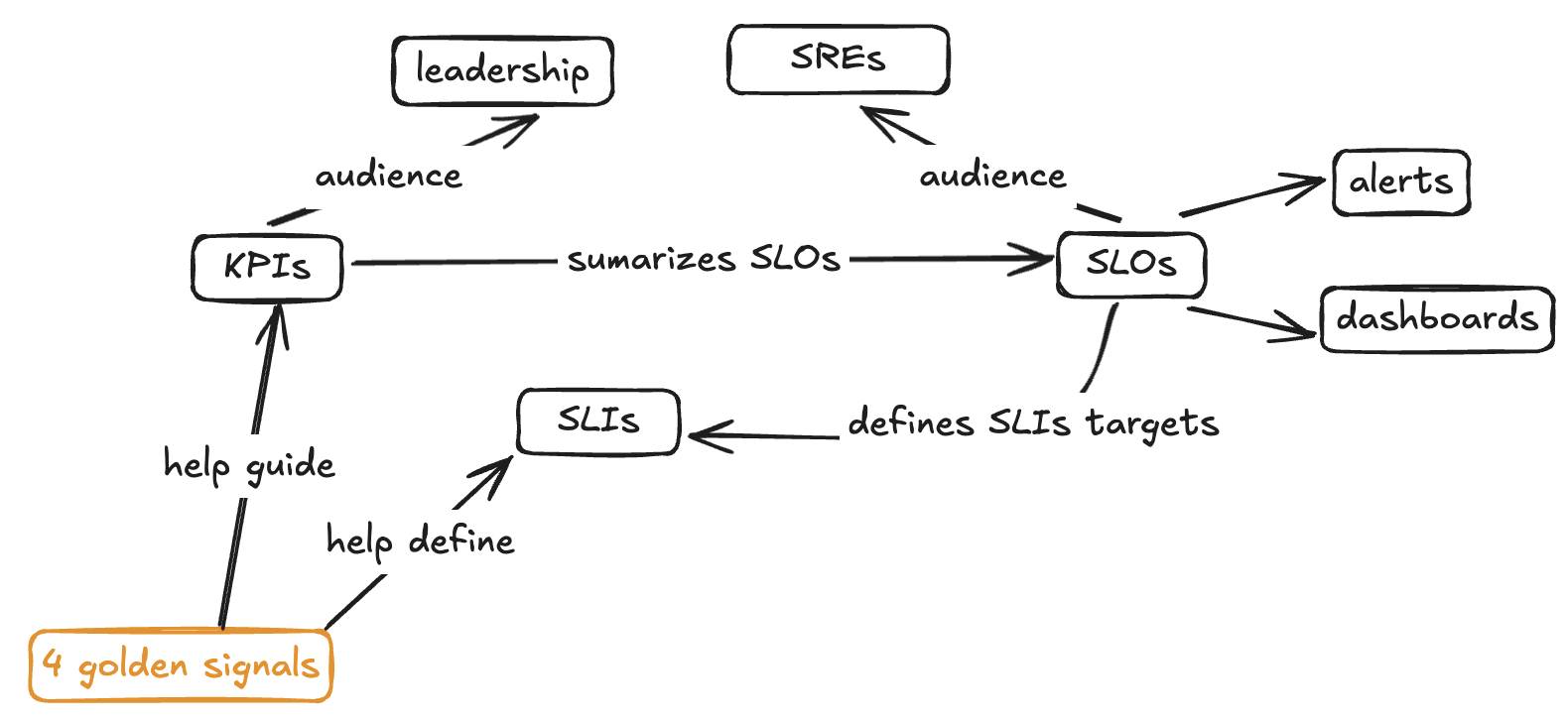
How can SLIs, SLOs, KPIs, etc be used to generate value to us and clients? We should never blindly try to define them. It’s not about just defining them or checking a box… it’s about achieving our performance, resilience, scalability, security, capacity planning, etc goals. So, define these goals first and then work on defining these indicators, objectives, results, etc.
Bringing everything together in a valuable and constructive/scalable way is harder than one might think. People and teams come and go from the company and ownership of components can change unexpectedly, e.g. a disbanded team in GitLab. What happens with the alerts? What happens with the knowledge? Will the metrics that that team tracked get the same attention?
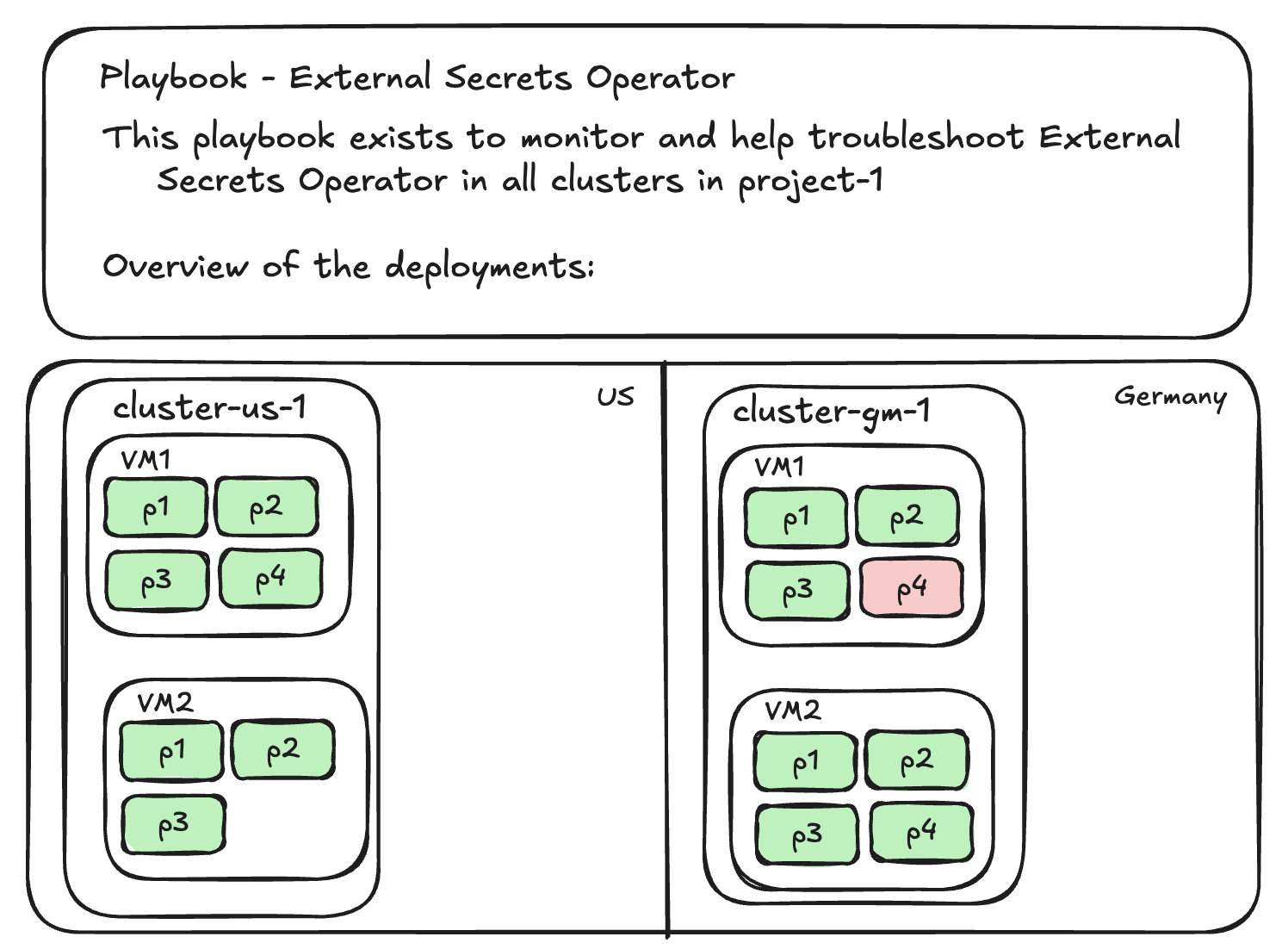
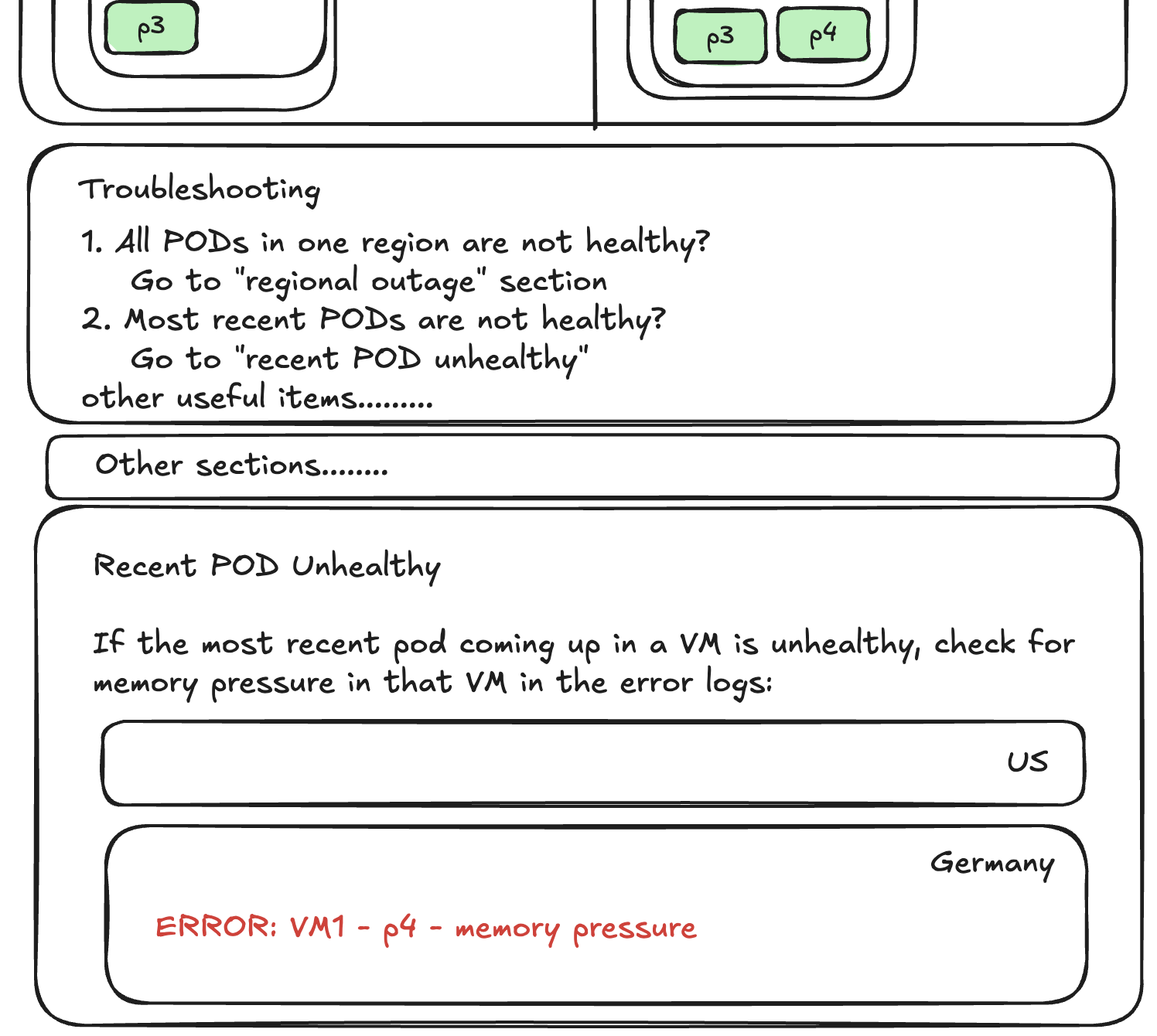
So far, the most valuable approach I have seem is: playbooks. A good playbook has all the important content someone needs to react to alerts: dashboards, instructions on how and what to troubleshoot, runbook information, and DR plan information in 1 place.
Playbooks
Playbooks so far have proved to me to be valuable to any team size (startup and big corp) and for all types of engineers in any level (entry, senior, etc).
-
Playbooks are where we go to check what to do when we get an alert.
-
A playbook is not a static “document” like runbooks, it’s a live webpage.
-
Playbooks are where we have runbooks, with troubleshooting knowledge, with dashboards, with alerts, with logs, with whatever else we find useful to help us achieve our performance, resilience, scalability, security, capacity planning, etc goals.
Draft of a playbook