Overview
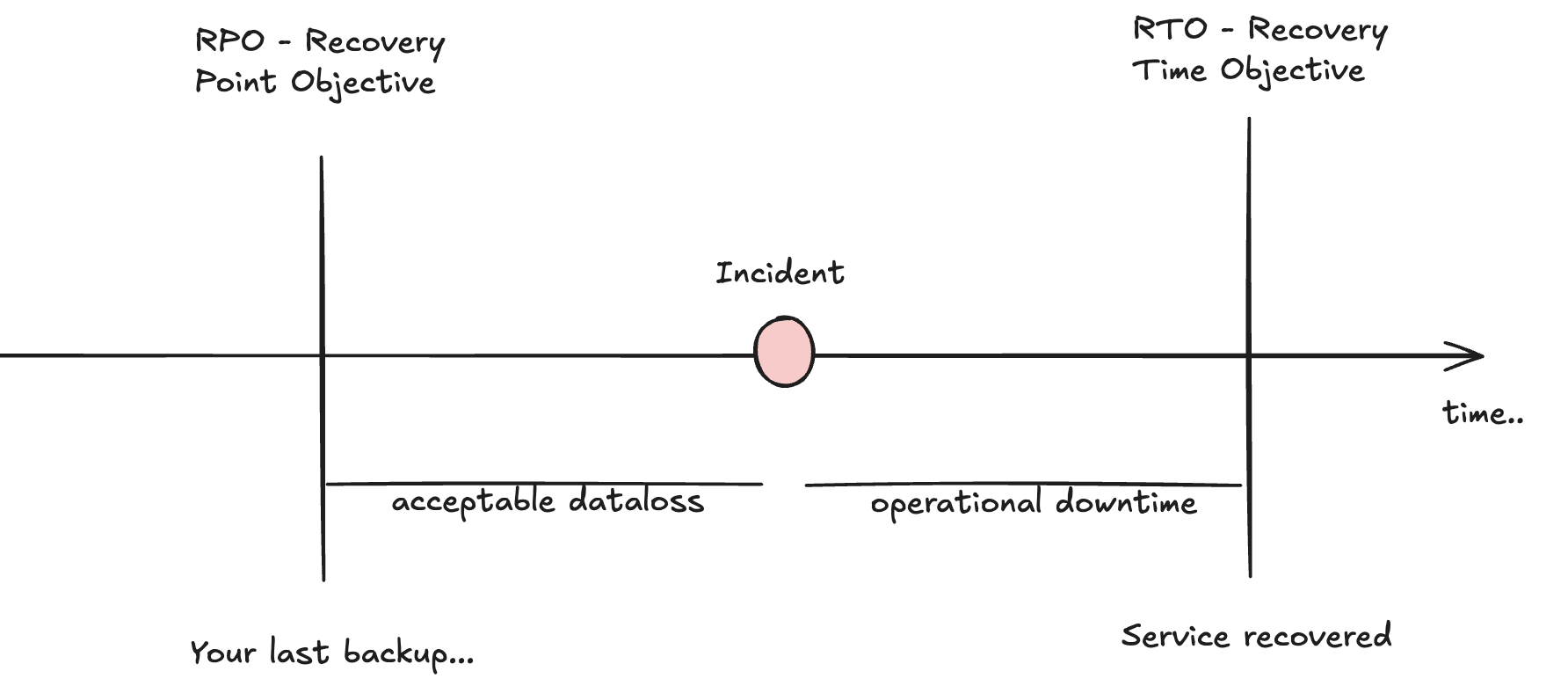
When talking about Disaster Recovery it’s always good to refer to RPO and RTO:
There are many options here and my number 1 recommendation is that, if you can afford and/or there is a good use case, use active/active computes, such as clusters/vms/managed isntance group/etc. If having active/active with a “smart DNS” that does health checks for the compute instances is not a good fit (infra that doesn’t require something around 99.99% uptime, for example) then you might want go over alternatives in the following table:
| DR Type | Stateless RTO;RPO | Stateful RTO;RPO | Pros | Cons |
|---|---|---|---|---|
| Hot-Hot | secs;zero | ~secs*;~zero | Virtually instant; | High cost; complex state sync; data conflicts must be handled |
| Hot-Warm | 1–5mins;sec to mins | 5–15mins;mins | Can be cost-effective; reasonably fast; can sync state periodically | Stateful sync must be reliable; warm infra still incurs cost |
| Hot-Cold | 10–30mins;~1 hour | 30–90mins;30mins+ | Low cost; full control over infra bootstrapping | Slow recovery; |
*potential dataloss depending on the persistent storage and what is being stored (maybe a client loses a session or, depending on the setup we could lose a DB transaction).
RTO
RTO is relatively straight forward - do you want the system to recover quickly? hot/hot; maybe some disruption is ok hot/warm; you want to save money and recovering under 1h is not a priority then hot/cold.
RPO
RPO is way more complex as it will potentially incur dataloss - the real question is: what data is ok to be lost? and the entire DR is not about the compute instances anymore but for the data itself.
There are two main scenarios: 1. It’s ok to lose the data. 2. It’s not ok to lose data:
I will use clusters for the example, but it should apply to any compute.
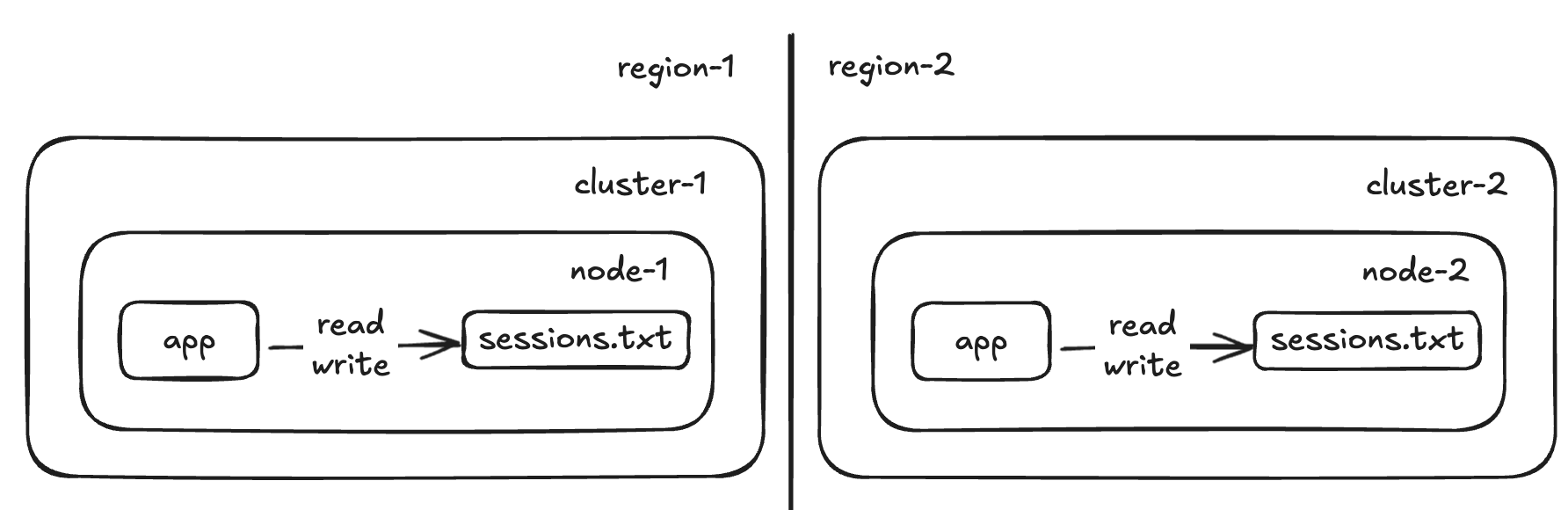
- Is it ok for a client to have to login to your app again after a disaster? So, in your design you can store that data in memory…
- It is NOT ok for a client to send a money transfer, see a “transaction successful” and then the next day they see it was never actually transferred. In this case you want to replicate the data and only acknowledge that it was successful when it’s replicated in all regions.
Hot/Hot
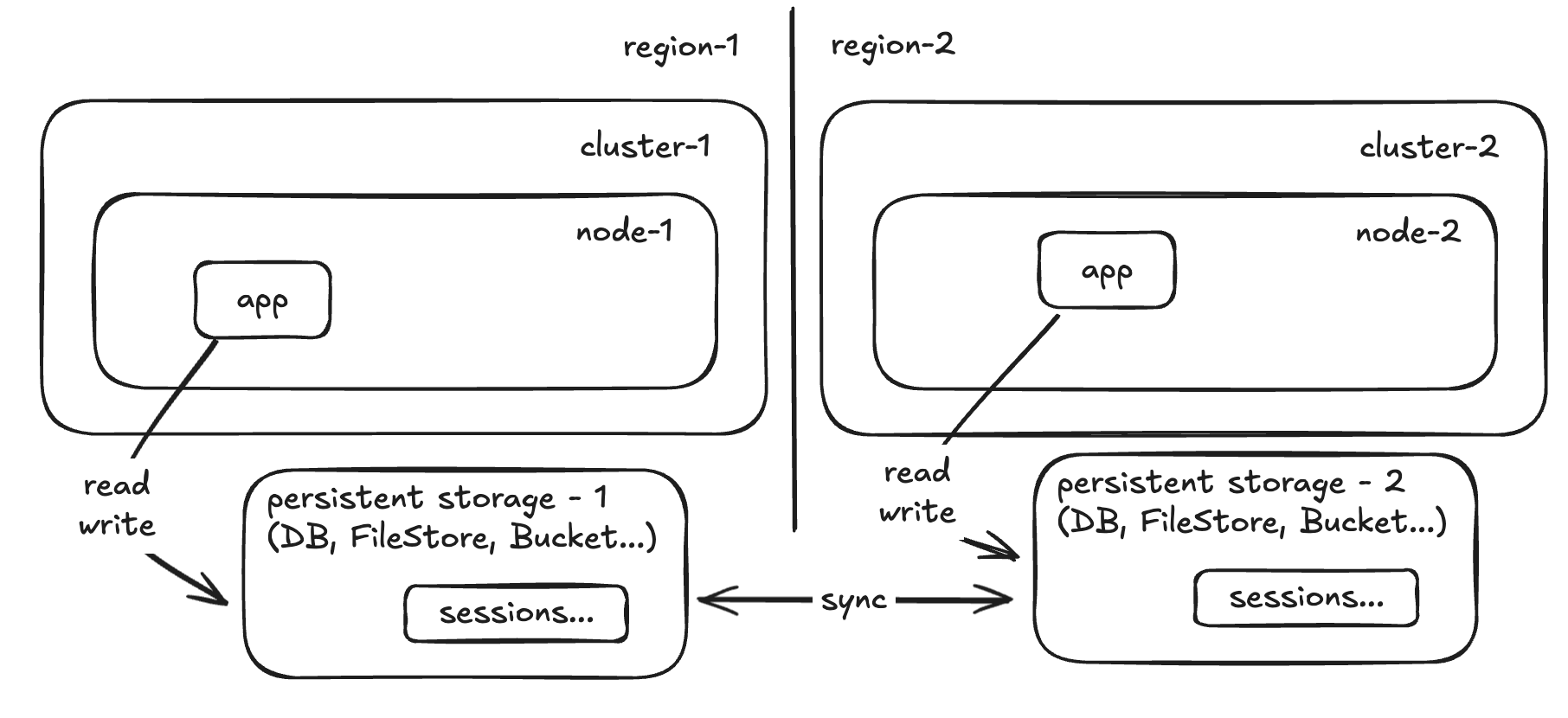
When in hot/hot, as soon as a region fails the other region should be up and running independently.
There should be some expected impact in case of sticky sessions and/or how your stateful app uses it’s state… but user impact can be minimized if you replicate/externalize the entire state (like in the image above), for example.
Hot/Warm
Step 1:
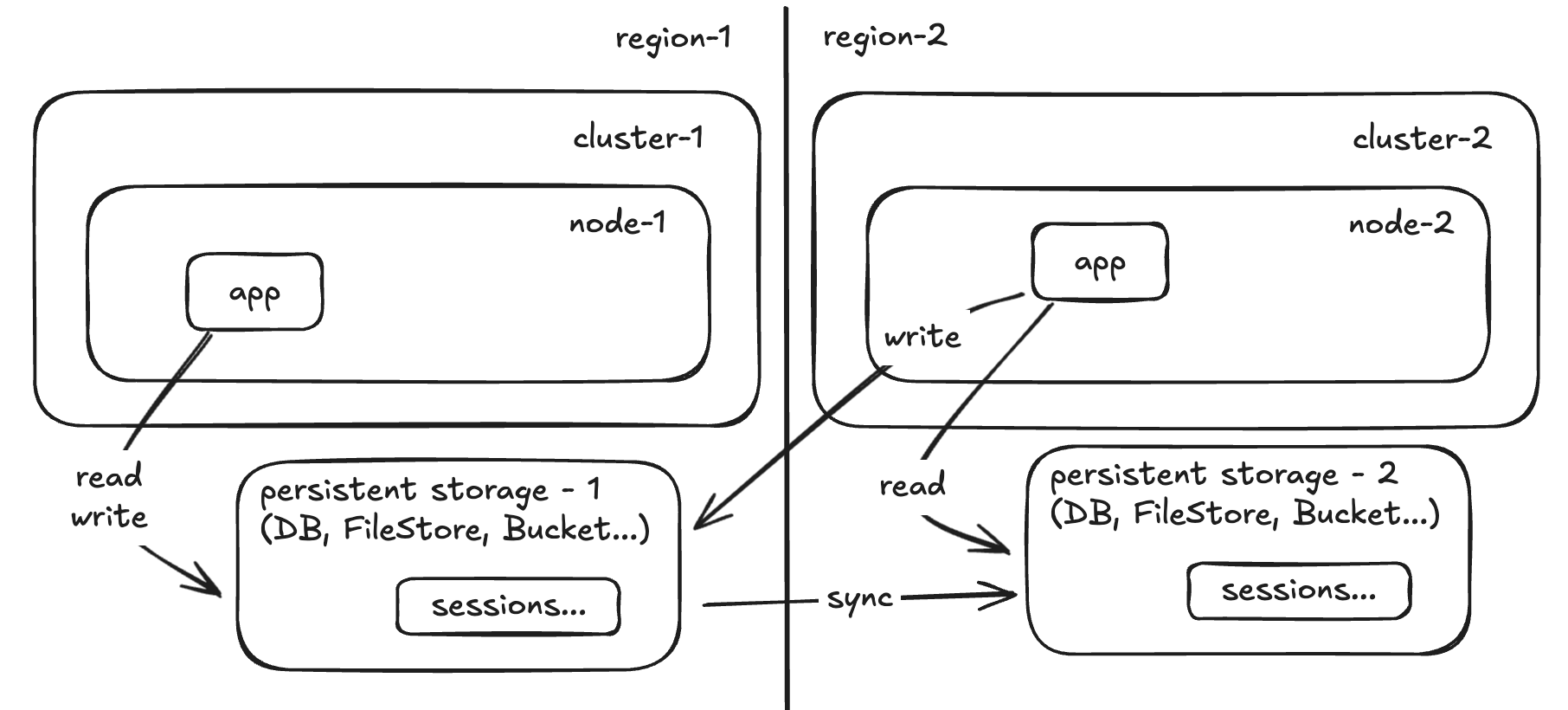
Step 2:
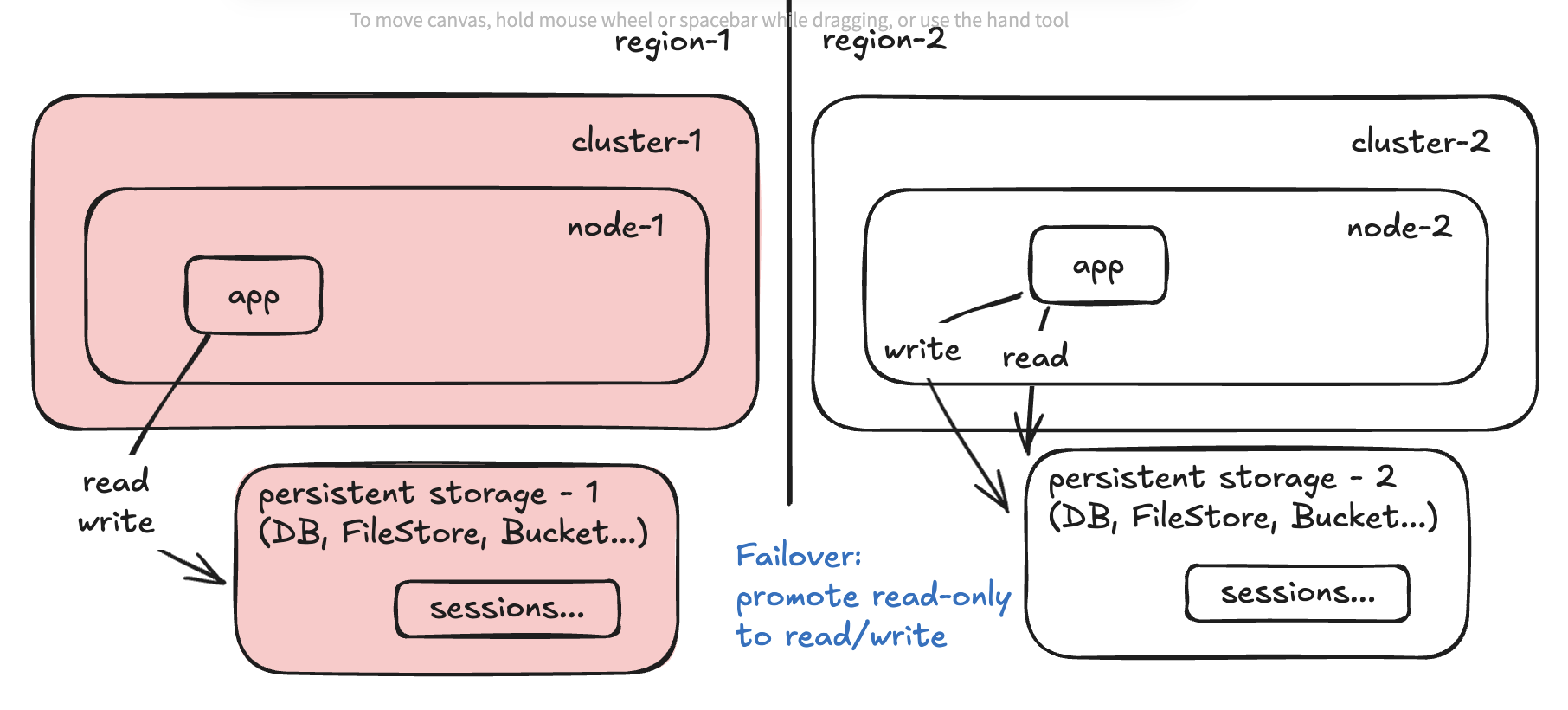
Step 3:
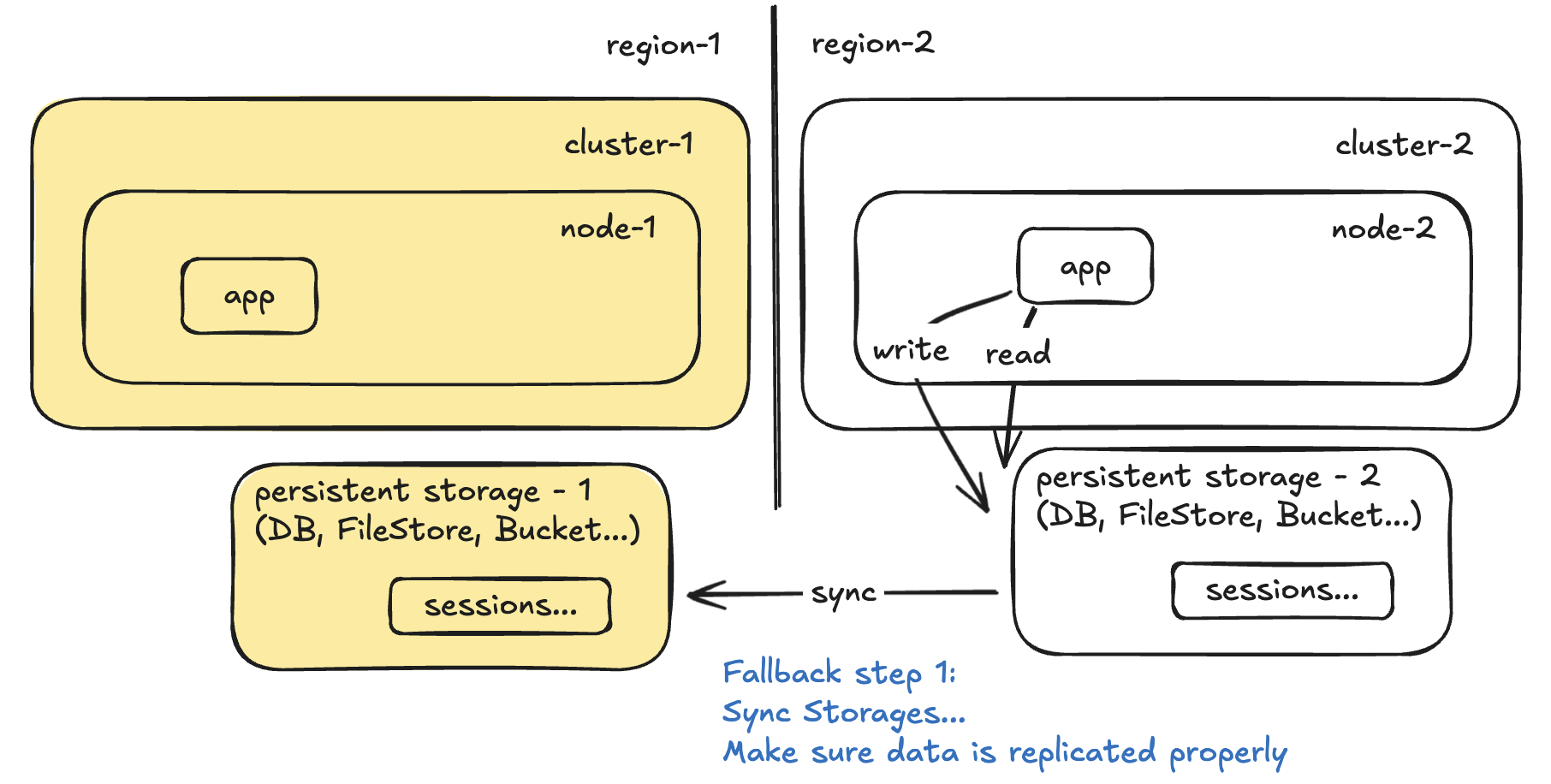
Step 4:
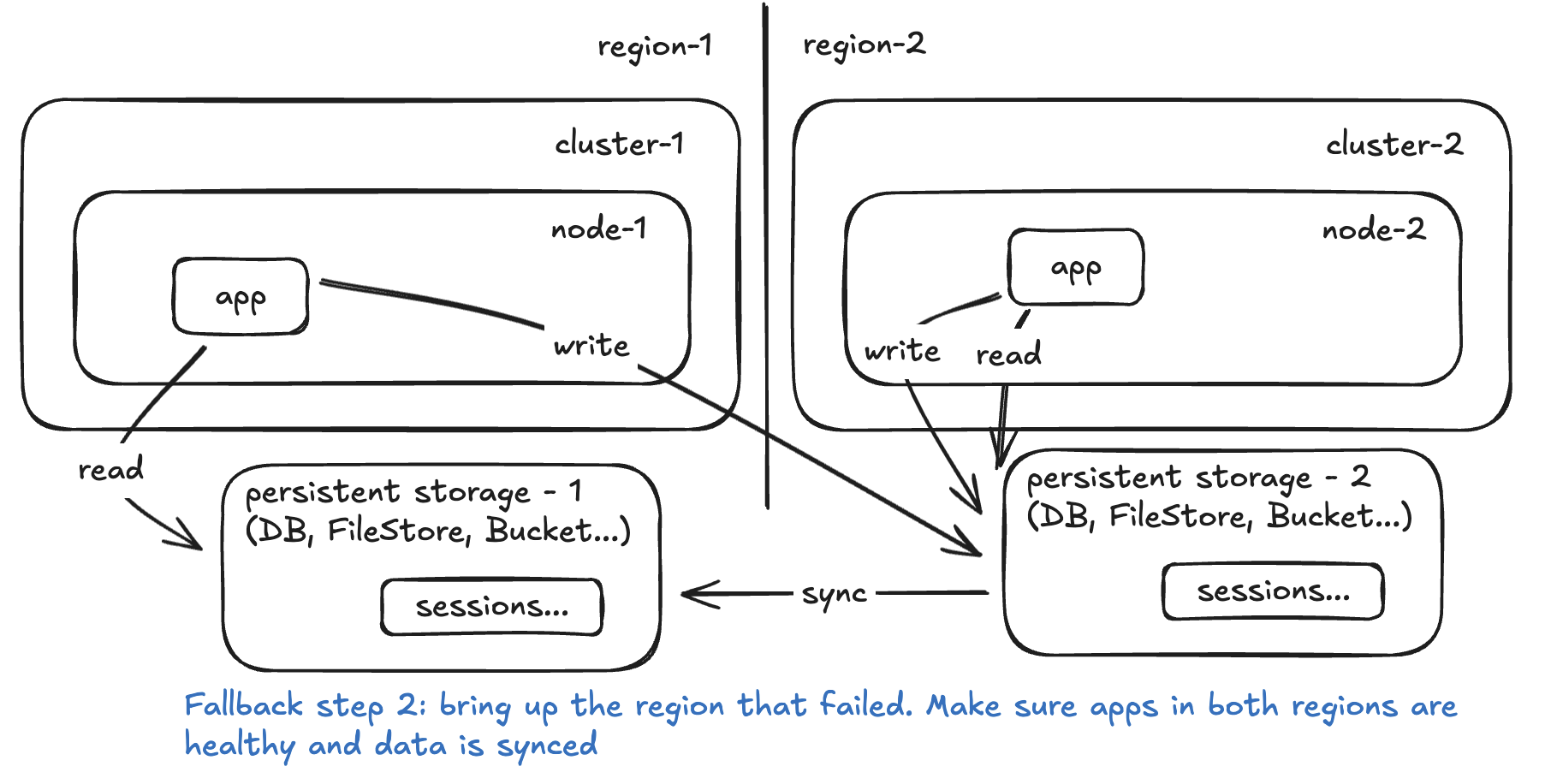
Step 5:
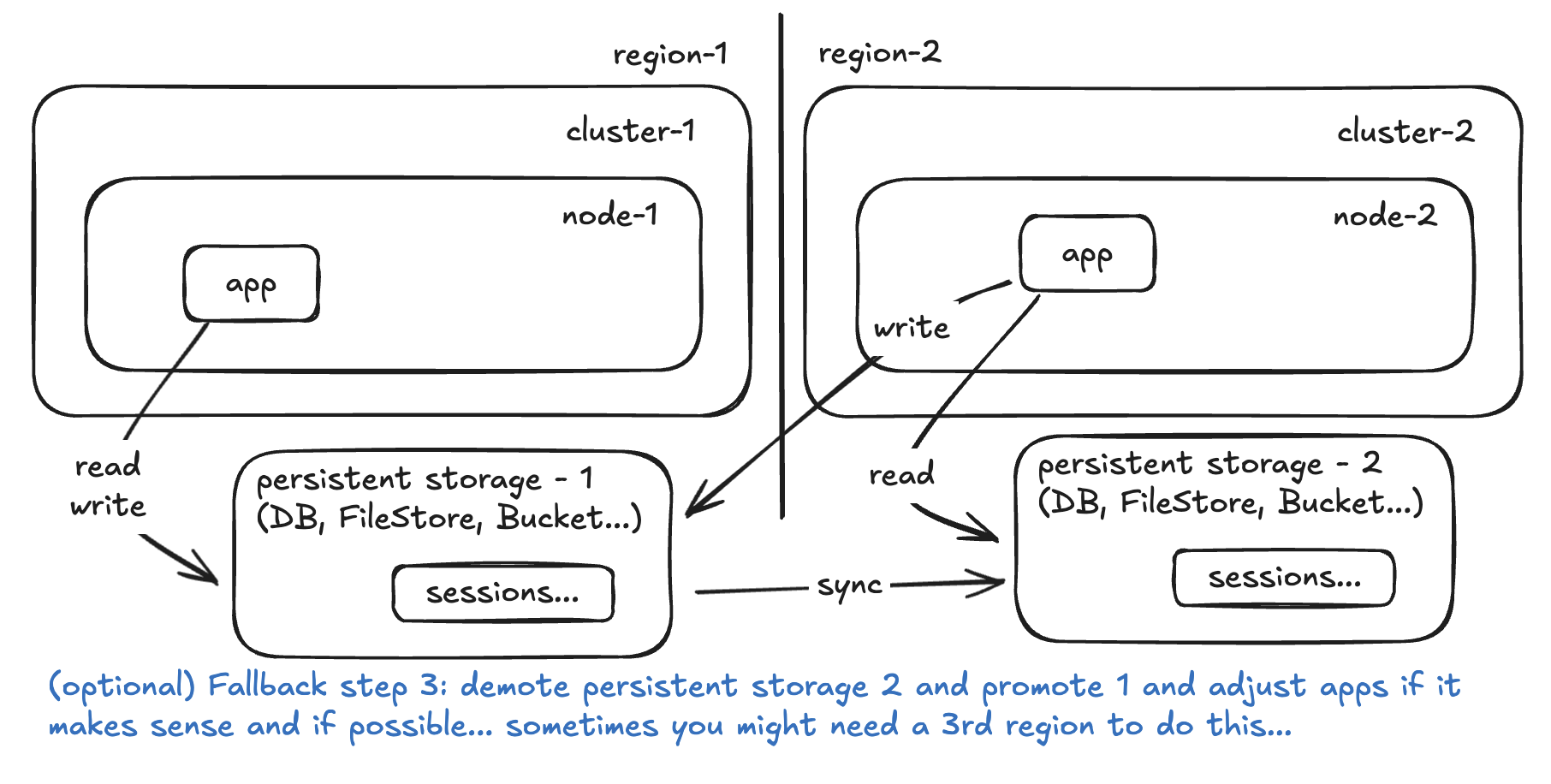
How often are you syncing the persistent storages? That’s your RPO. How long will it take to configure and scale up the app and it’s dependencies (lbs, health checks, etc) in the cluster? That’s your RTO.
When in hot/warm, some of your infra is already there and there might be some automated or manual steps to redirect traffic and/or reconfigure the persistent storage and/or app.
The objective is to have the region that is alive to serve traffic normally, so walk backwards to a point that works for your scenario and identify where you want your infrastructure to be so you can later walk forward to bring it up again - if you go too far back you will be in the hot/cold scenario…
Hot/Cold
Step 1:
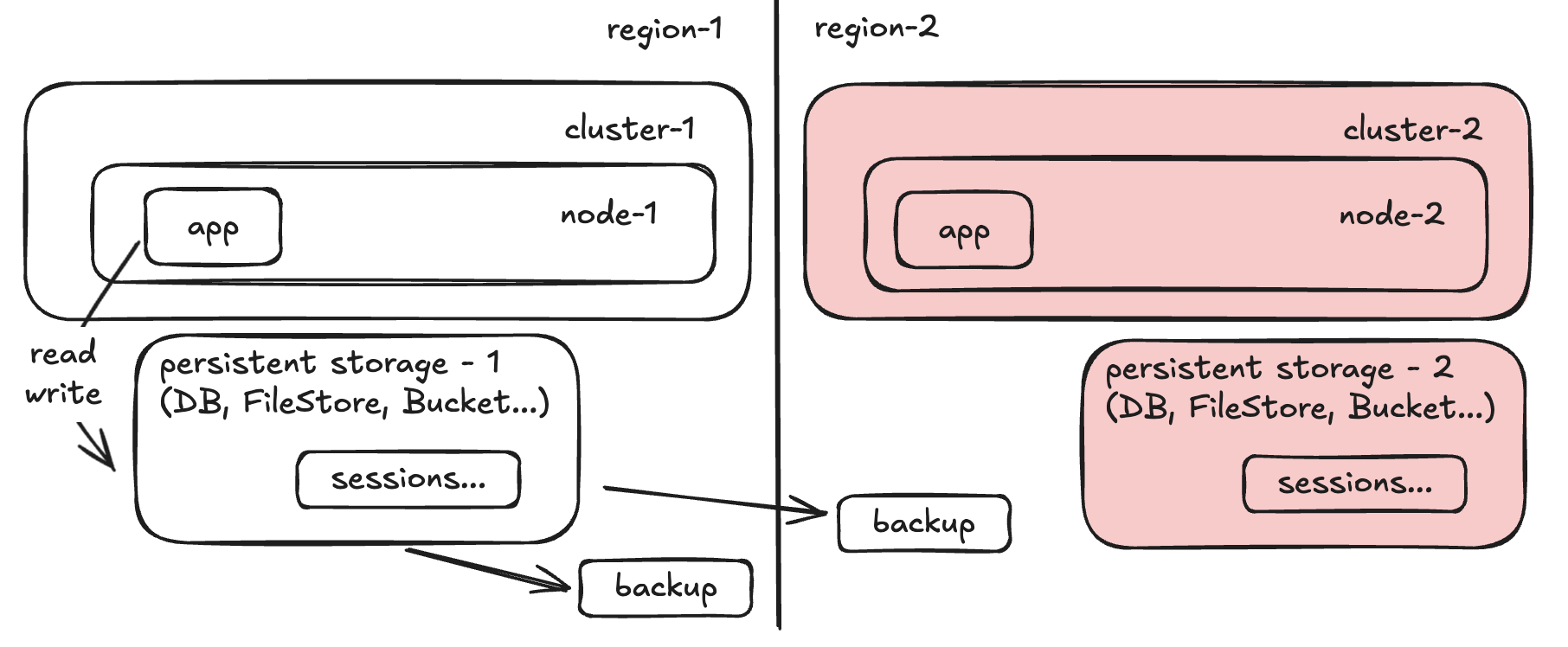
Step 2:
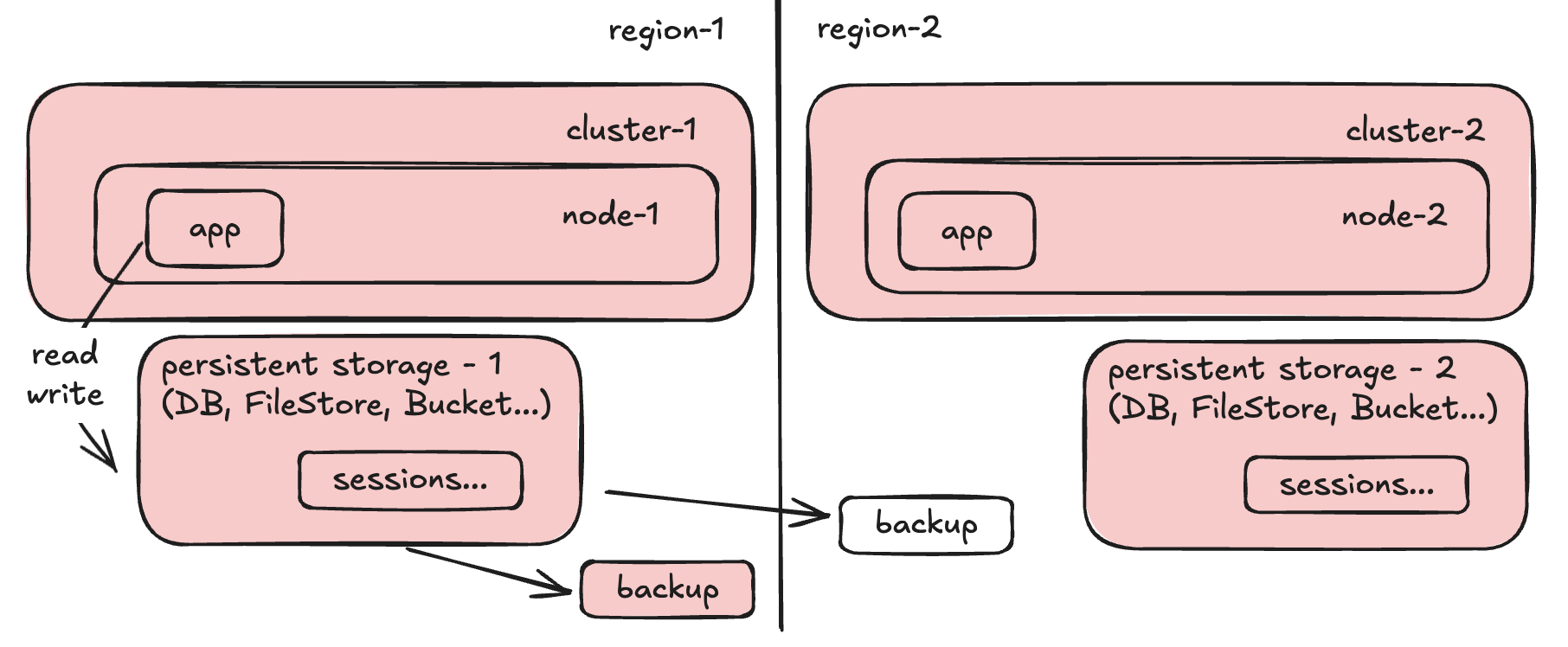
Step 3:
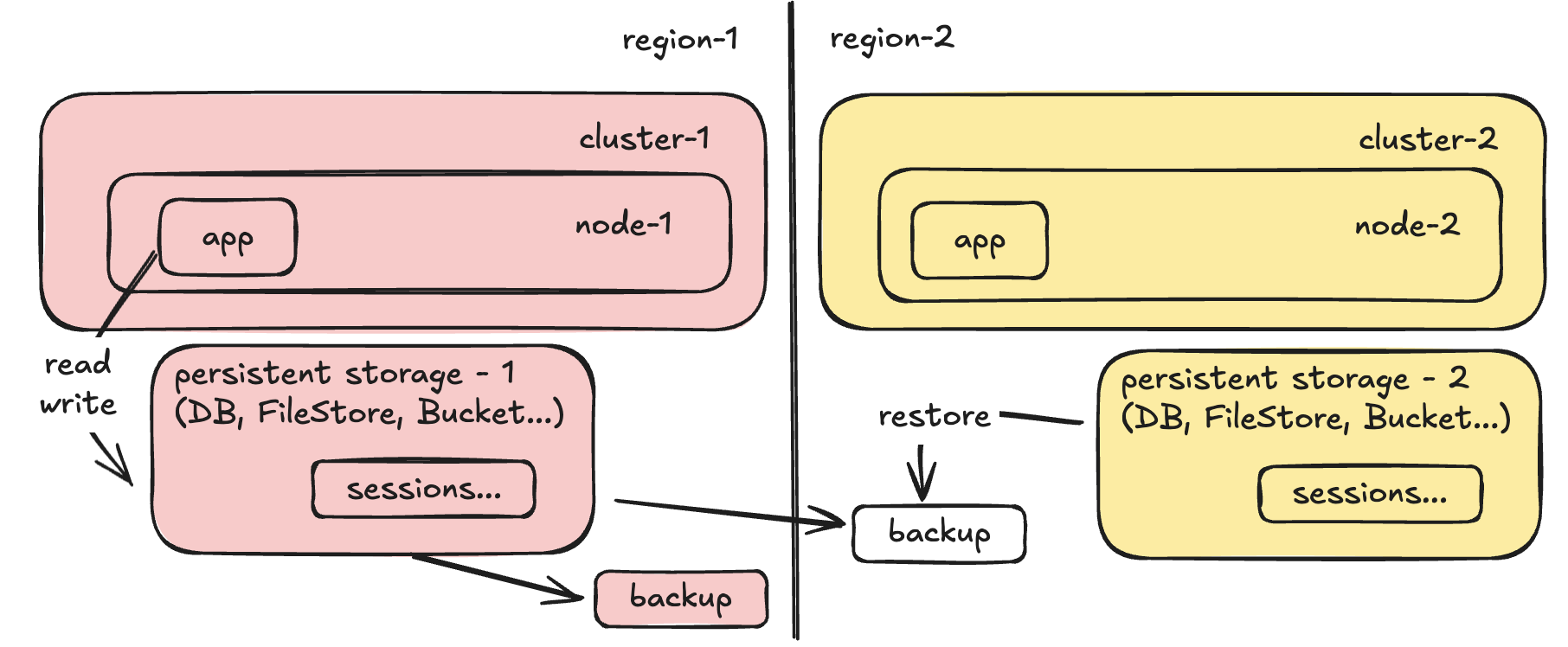
Step 4:
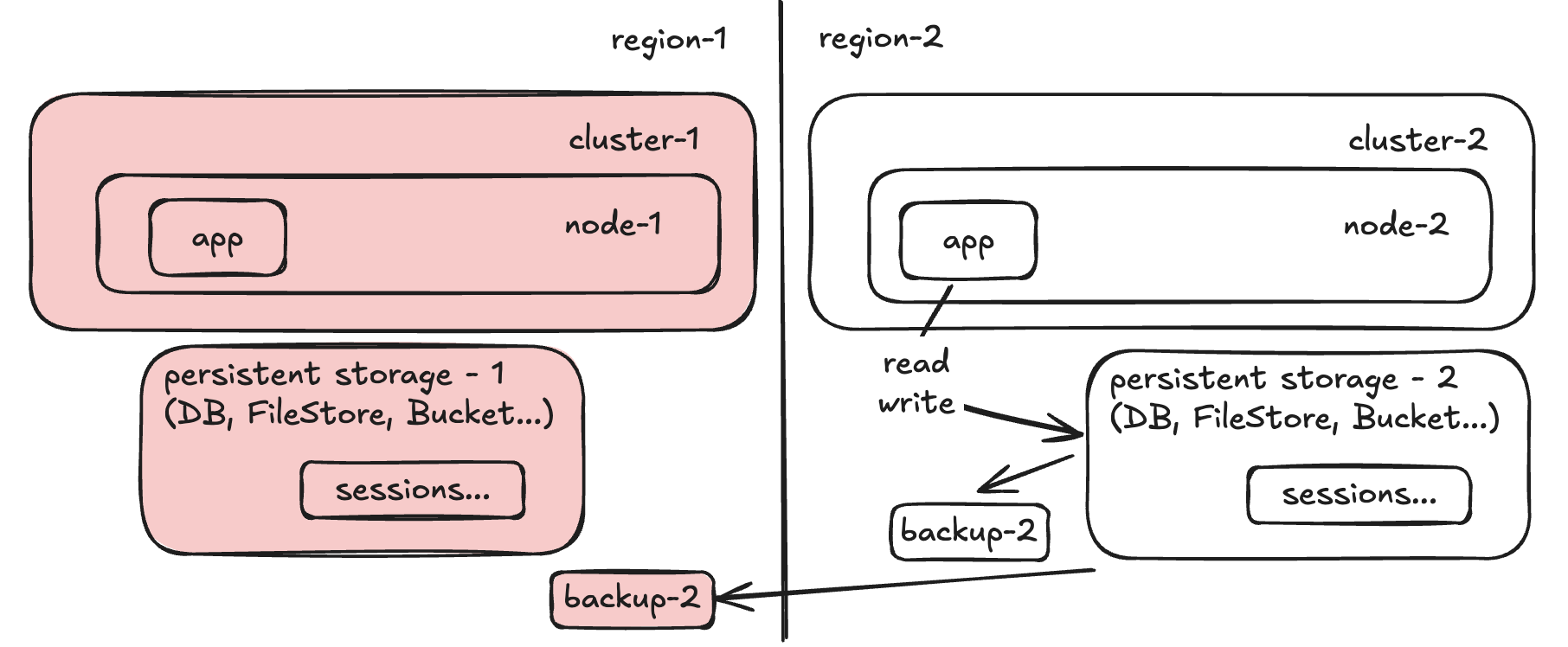
Step 5:
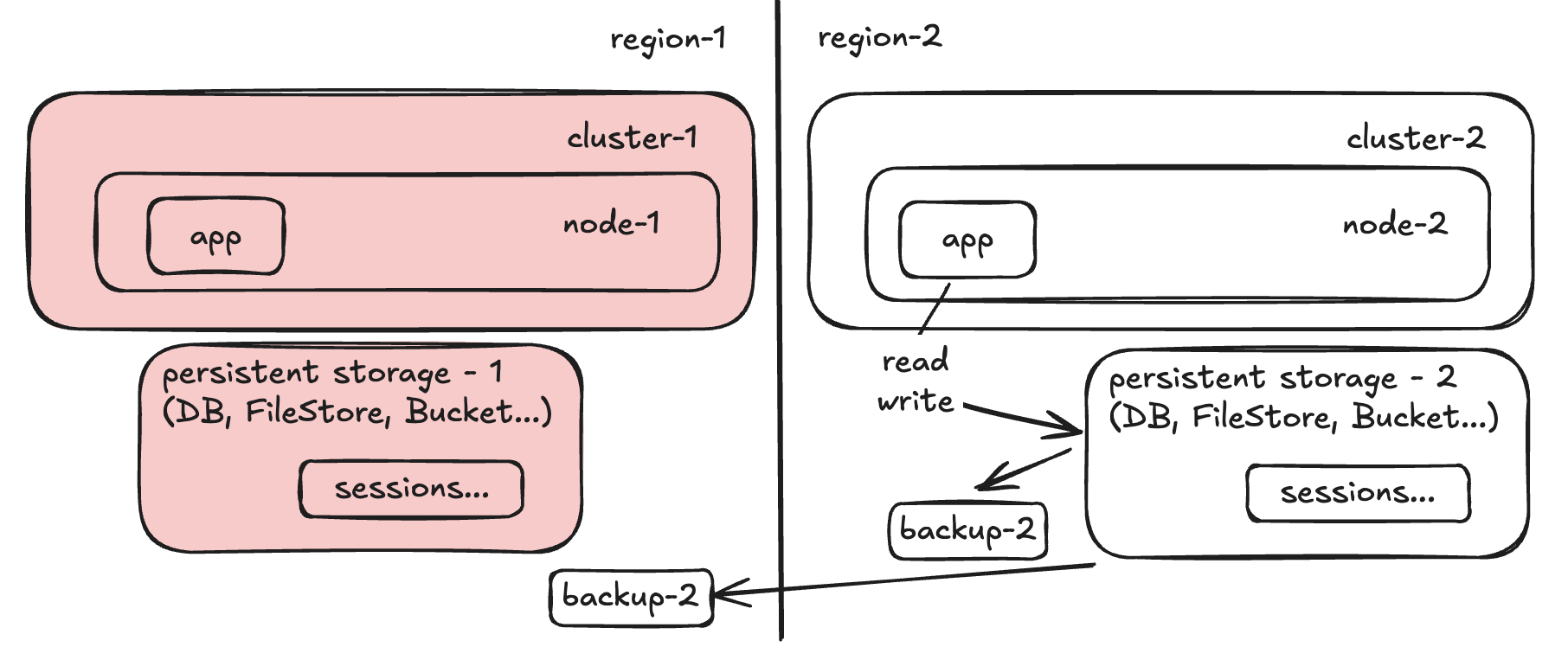
How old is your latest backup? That’s your RPO. How long will it take to bring up the new cluster, configure all dependencies (lbs, health checks, etc) and bring up the app? That’s your RTO.
With some certainty you will have dataloss as backing up takes time and you might not really want to take snapshots every second - at that point you should just sync the storages…
Bringing up the app can be straight forward if your infrastructure is very simple, but if you run hundreds of apps and there are dependencies, such as: external-secrets-operator, a hashicorp vault instance, etc even IaC won’t make these things to be brought up instantly, so you will have downtime.
Notes
One additional risk I have faced before, is not having enough Node/VM availability in a region to scale your backup cluster. If you decide to use hot/cold or hot/warm you have to accept this risk.. Sometimes you might have everything ready to DR to another region but then you can’t spin up a machine because the cloud provider just doesnt have more machines available - it’s not your projects cpu limit, they just dont have.. be mindful of this and know your infrastructure limits. Talk to the cloud provider and request to reserve resources in a region if possible and necessary.